Core System
agentic canvas
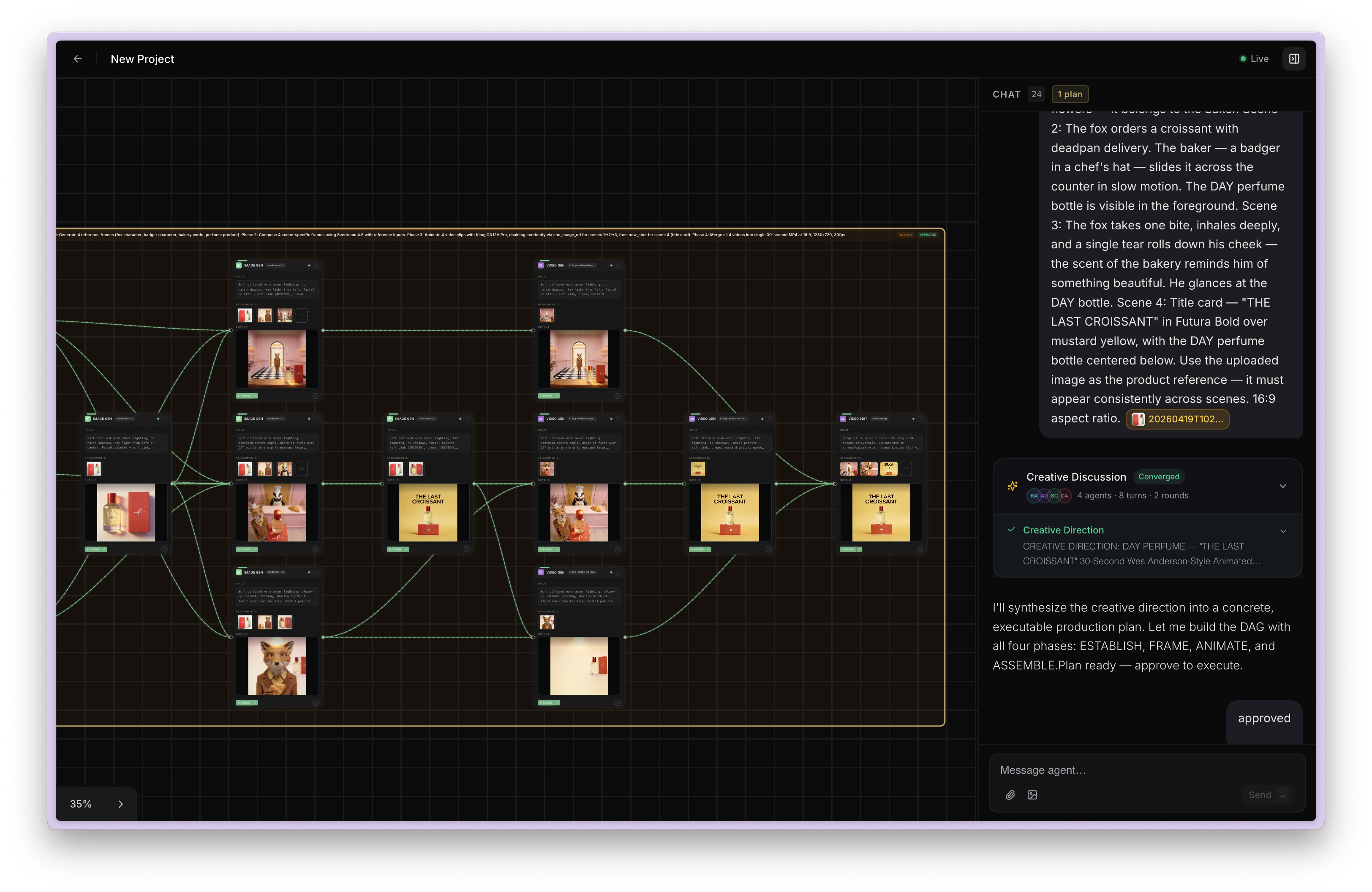
A canvas-native agent system that converts natural language into validated, editable, executable creative DAGs.
Stage 01
director
Routes the turn as quick generation, full creative planning, edit, chat, or bulk generation.
Full runs can launch persona debate before planning.
Stage 02
planner
Builds steps, dependencies, and visual groups using the live model catalog, uploaded assets,
context library, and model capability metadata.
Stage 03
edit agent
Repairs invalid plans and handles targeted edits from selected canvas nodes. Every graph edit is
tracked so affected downstream nodes can be marked for regeneration.
Stage 04
executor
Runs ready DAG levels concurrently, syncs realtime canvas state, calls the job router,
and retries or reroutes failed nodes without stopping independent branches.